

Modern artificial intelligence algorithms are based on methods of analyzing correlations and statistical relationships in big data. When the machine makes a decision, it scans the embedded database of texts, finds the most frequently occurring connections, and based on this analysis gives the answer.
A good illustration of this is the visualization of the RoBERTa library, developed by the Allen Institute of AI, published in mid-2019.
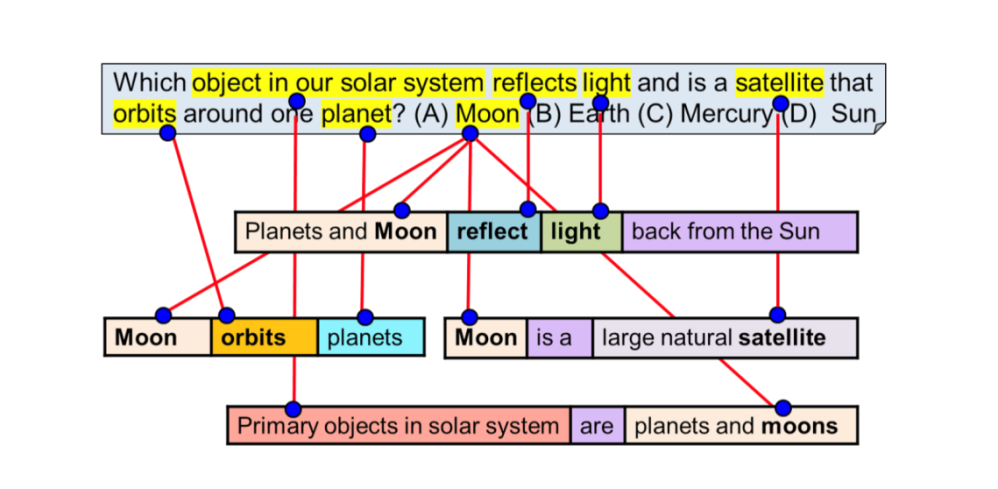
Such solutions, which are the most advanced, can answer only narrow questions, such as those implemented in phone voice assistants - Siri, Alice, Google Assistant, Amazon Alexa.
The most advanced indicator of the level of understanding for AI systems - the SuperGLUE metric was launched by DeepMind and Facebook in 2019 to determine the degree of understanding of the text by the machine. This is a short test of eight typical questions for understanding the meaning of the text (sentences). The subject should read the description of the situation and answer the question of how to interpret it.
The complexity of the task roughly corresponds to the level of primary classes. Current accuracy - up to 80%.
The new Up Great contest is aimed at creating new approaches in AI that will allow the machine to understand and take into account how the cause and effect are related. Such approaches will be useful in the processing of natural languages, and in many other areas of application of AI.
For the implementation of technologies for understanding the meaning of texts, the field of education has been chosen, since for educational texts there are proven methods of a relatively objective assessment of the quality of the text. In addition, training is an industry that is socially significant and in need of innovation.
The competition will create a technology that can find semantic errors in any texts and report it in real time.

The contest is held in the field of using technologies of machine text analysis to improve the quality and speed of identifying factual and semantic errors in the academic essays. Technologies developed as part of the competition will be able to become the core of a wide range of products.

Natural language processing (NLP) is a dynamically developing area of artificial intelligence that is in the focus of a large number of specialists and at the same time has a rather low “barrier to entry”: to develop NLP solutions, a specialist does not need significant investments in equipment and fundamental scientific knowledge.
CONTEST TIMELINE
If the technological barrier is not overcome in the current cycle, the next one is launched.
First cycle took place in November 2020. As no team could solve the task, the contest continues with the 2nd cycle to be launched in autumn 2021.
Registration is available anytime.
FAQ
Any Russian or foreign legal entity and individual is invited to participate in the Up Great contest READ//ABLE.
To take part in the contest the team should consist of at least 2 and maximum 10 members, including the team leader. The team may consist only of citizens of full legal age or equivalent as provided by the emancipation of minors procedure according to the legislation of the Russian Federation. If you don’t have a team yet — we will help you find one or form a new team.
For Russian speaking participants: to register for the contest, please fill in the form https://crm.nti.fund/.
For non-Russian speaking participants, please follow the link
May you have any difficulties with the form, do not hesitate to contact us at ai@upgreat.one.
The contest was launched in December 2019. It is divided into several cycles of the tests. Each cycle consists of registration, qualification (access to the tests) and the tests. First tests take place in November 2020.
Results of the first cycle will be announced in mid December 2020. After that we will publish information on the next cycle.
Registration is open anytime.
Testing includes following stages:
1. Technical. Participants connect to the server, download the dataset, detect errors and upload back to the server.
2. Main. Participants receive new essays that have not been published before and which teachers and specialists have not seen yet. They do the markup and upload back.
3. Verification. A technical stage, when the technical commission and the panel of judges check the results of the teams and the essays for an objective determination of errors and the level of the technological barrier. Expert results are automatically compared with teams’ results.
4. Announcement of the results
Sample text files in Russian and English are already published. Participants can train and test their algorithms using any other data as only the end result will be taken into consideration.
It will be evaluated by comparing with the average number of errors which a real teacher or specialist can find in the same documents in a limited time.
Technical guidelines with the detailed description of the evaluation framework are available.
Then the edited txt-file is uploaded back via API and evaluated through the platform using the software solution provided by the organizers.
The technical guidelines will describe the procedure in detail.